
Notre mission
Chez Qucit, nous travaillons à rendre les villes plus agréables et durables. L'un des piliers de la qualité de vie en ville est la mobilité active. Elle permet un accès équitable et écologique aux différents services urbains. Nous soutenons les opérateurs de micro-mobilité partagée (vélos, trottinettes, scooters) pour les aider à simplifier leurs opérations. Nous optimisons la logistique de leurs opérations de terrain. Les objectifs : augmenter le taux d'utilisation des véhicules, garantir le respect des niveaux de service attendus par la collectivité, réduire les coûts opérationnels, en simplifiant la gestion des équipes et en limitant la consommation d'énergie.
Qucit Bike : simplifiez vos opérations terrain
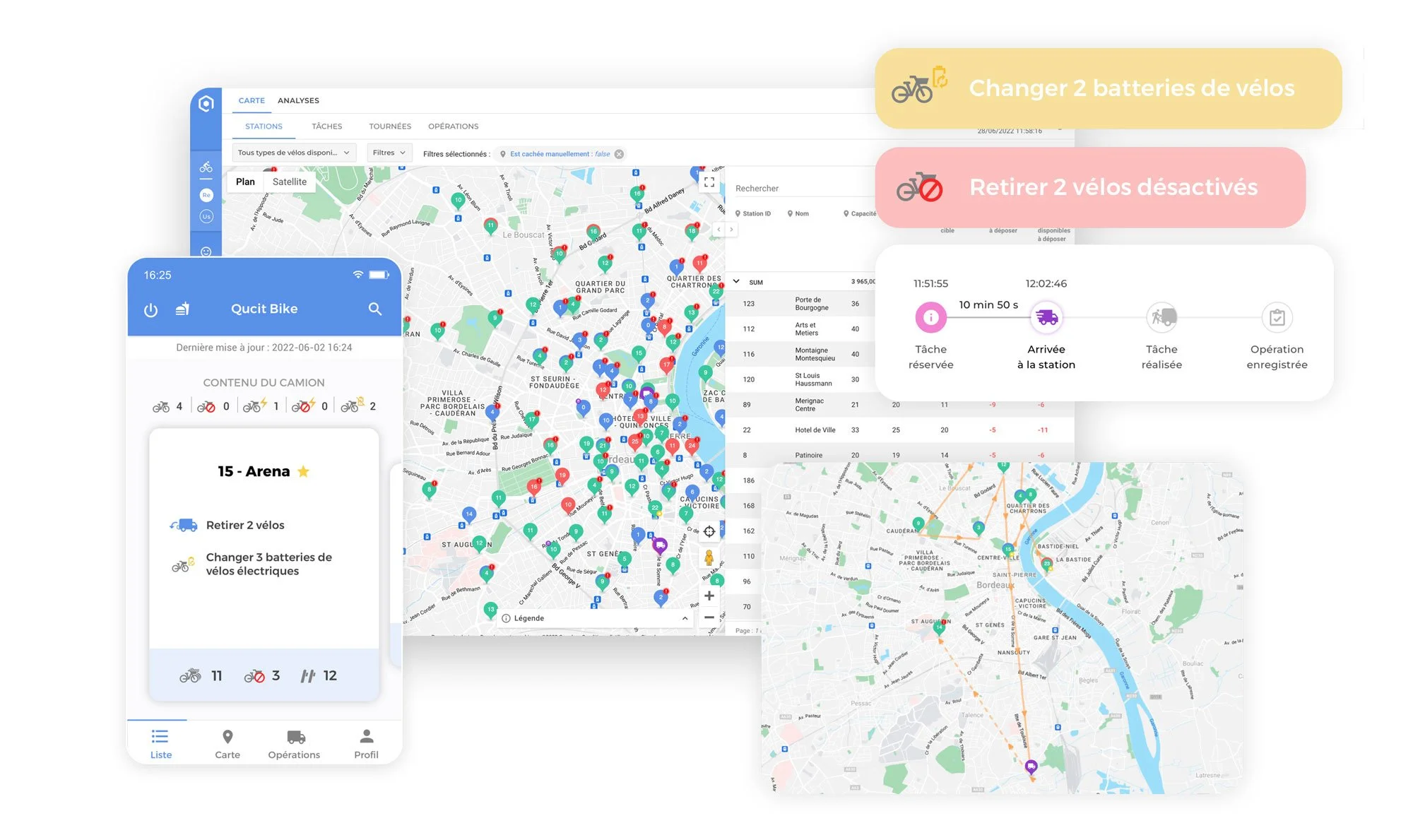
Qucit Bike est le logiciel leader pour l'optimisation logistique des opérations terrain des systèmes de micro-mobilité partagée.
Composé d’un tableau de bord pour les managers et d’une application mobile pour les opérateurs et techniciens sur le terrain, il vous permet d’automatiser :
Le déploiement et le rééquilibrage de votre flotte
La ramasse des vélos cassés
L'échange de batteries
Le contrôle et la maintenance des stations
Avec Qucit Bike, simplifiez et optimisez quotidiennement l'ensemble de vos processus d'exploitation, du rééquilibrage à la maintenance !

Diminuez vos coûts d'exploitation en optimisant la logistique des opérations terrain

Respectez tous les types de niveaux de service attendus par la collectivité

Augmentez le taux d'utilisation des véhicules grâce au rééquilibrage prédictif
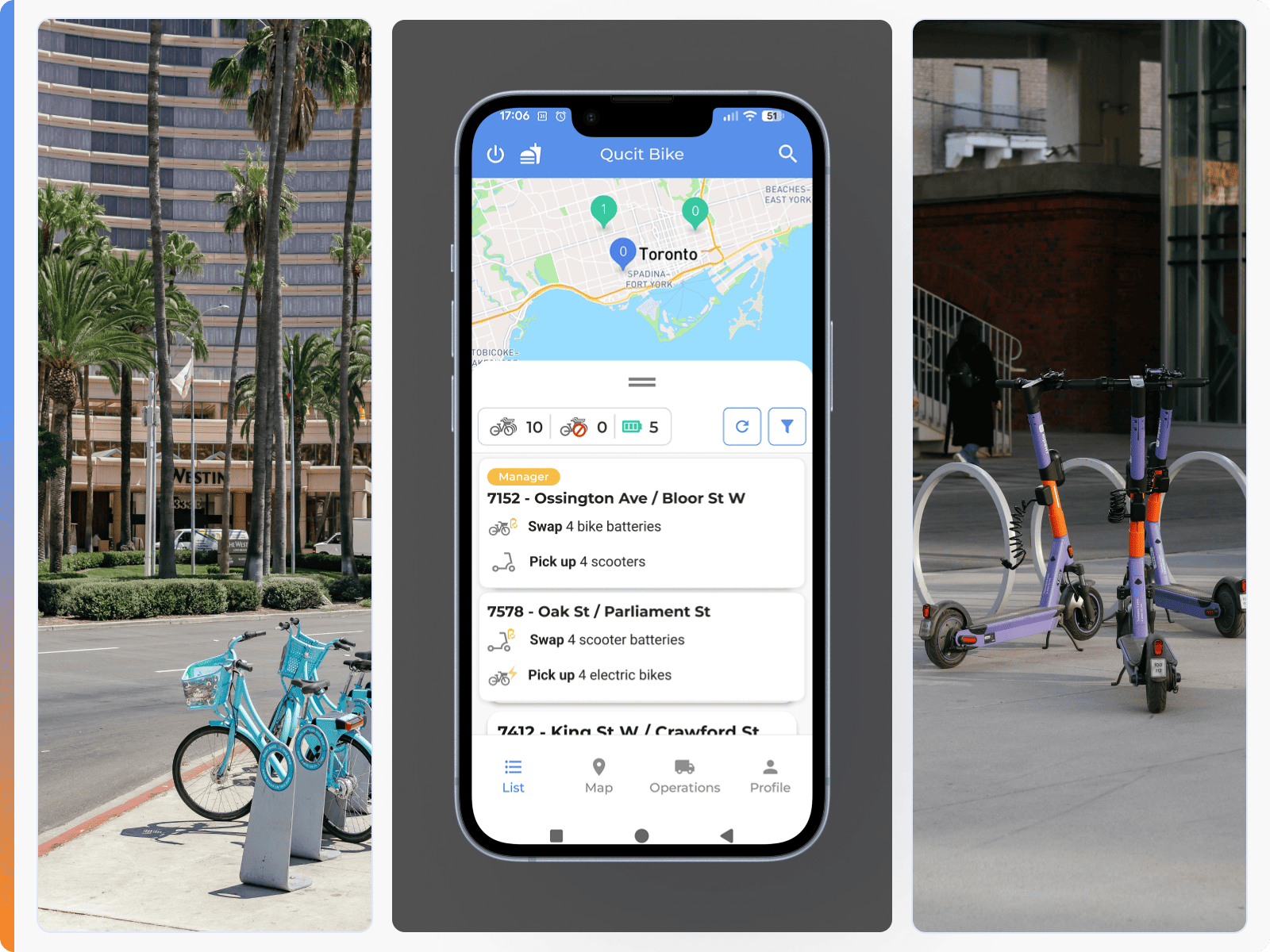
Nouveau :
Qucit s'adapte
à tous vos véhicules
Votre flotte évolue, notre solution s'adapte. Vélos, vélos cargo, trottinettes... Qucit vous recommande les bonnes actions pour chaque type de véhicule, même dans les configurations les plus complexes. Simple à mettre en place, il s'affine au fil du temps grâce aux retours du terrain, pour des opérations toujours plus précises et efficaces.
Qucit Bike fonctionne avec tous les types de vélos
Vélos mécaniques
Vélos électriques
Vélos cargo

© PBSC
Quelle que soit la solution de stationnement choisie
Stations physiques
Stations virtuelles
Free-Floating
Hybrides (une combinaison des solutions de stationnement mentionnées ci-dessus)

Nous aidons nos clients à façonner les villes grâce à la mobilité partagée

véhicules partagés

pays

trajets par an

villes
Leurs témoignages

PeDAL MOVEMENT - LOng beach
“La mise en œuvre de Qucit a apporté des avantages tangibles en termes de productivité et d'efficacité de la communication. En automatisant les tâches routinières et en rationalisant les flux de travail, les employés peuvent se concentrer sur des activités à plus forte valeur ajoutée, ce qui se traduit par une augmentation globale de la productivité. L'organisation a bénéficié non seulement d'une efficacité accrue, mais aussi d'un environnement de travail plus cohérent et rationalisé.”
Josh Calhoun, Manager Général des opérations de vélos en libre service
3 continents .
14 pays .
+30 villes .
3 continents . 14 pays . +30 villes .















Focus sur la mobilité partagée : innovations, défis et évolutions

